Original description:
We found a site on which the flag is posted but it is hidden behind a large number of captchas. As they understood, the owner does not like bots and created his own captcha generator. Although I’m not a robot, I can’t get beyond 200. Go through the entire captcha and get a reward flag. P.s. Login and password are stored in the session.**
Problem:
You really need to correctly solve 200 captchas after each other. The timeout between captchas seems to be around 5-10 seconds, so it’s nearly impossible to do manually.

Once plotted, eroded, segmented and isolated, the letters to learn look like this:

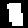
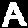
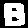
Solution
A script to repeatedly fetch, submit and solve capchas
- Start a session and repeatedly query reg.php and gen.php.
- Build an image detector - tesseract doesn’t work 100% reliable here, so we can only use it for semi-supervised labeling.
- Filter out the background noise by finding the most common colors with a
itertools.Counter(img.getdata())and set all colors that appear <30 times to black and the rest (the letters) to white. - Remove the remaining dots in the background with a “if all neighbors are 0, make it 0”-check.
- As the images are quite low resolution, erode all white text-pixels by 2 with
ImageFilter.MaxFilter(5). (Using a 5x5 kernel == erode by 2) - For segmentation, erode all pixels by 1 again, to make sure all letters are connected. Then use
skimage.measure(which expects black background, if background=0 isn’t set.) to get a numpy-array of segment-ids. Use np.where to get bounding-boxes. Cut out sub-images. - Resize all images to the MNIST-dimension of 28x28 (with no color channels) and save the labled images to a
labels/[lableid]/[randomname].png. Initial labels can be derived withtesseract.ocr_image(img). - Sort the images, build a classifier based on mnist with around ~100 images per class, then train a model. See build_model.py. A higher learning rate and less epochs should work fine.
- Use this model to classify all the letters, and build a position-letter map. Collect this map left-to-right to get the capcha.
- Send the captcha, check the response for the current captcha counter and retrain your model if your classifcation isn’t perfect yet. Use the debug-commands to see what went wrong in classification.
- Print the PHPSESSID once you reach 200, set your document.cookie to the correct value in your browser console and you can register.
Code Runner
# import tesserwrap; tr = tesserwrap.Tesseract()
# tr.set_variable("tessedit_char_whitelist", "0123456789ABCDEF") # no O
# tr.set_variable("certainty_scale", "0.1")
from PIL import Image, ImageFilter, ImageOps
from collections import Counter
import matplotlib.pyplot as plt
import requests
import cv2
import numpy as np
from skimage import measure
from io import BytesIO
import tensorflow.keras as keras
import threading
from multiprocessing import Process
import random
model = keras.models.load_model("model.keras")
def classify(letter):
global model
letter = np.array(letter.getdata(), dtype=np.float32).reshape((1,28,28,1))
return "0123456789ABCDEF"[np.argmax(model(letter))]
def detect(img):
cd = Counter(img.getdata())
cd = {color: cnt for color, cnt in cd.items() if cnt > 20}
WHITE, BLACK = (255,255,255), 0
for i in range(img.width):
for j in range(img.height):
col = BLACK if img.getpixel((i,j)) not in cd else WHITE
img.putpixel((i,j), col)
# filter out single wrong pixels, out of place
ic = img.copy()
for i in range(1,img.width-1):
for j in range(1,img.height-1):
s = 0
for l in range(i-1,i+2):
for k in range(j-1,j+2):
pix = img.getpixel((l,k))
s += pix[0] == 0
if s <= 1:
ic.putpixel((l,k), BLACK)
img = ic.convert("L")
# erode image
img = img.filter(ImageFilter.MaxFilter(5))
ic = img.filter(ImageFilter.MaxFilter(3))
all_labels = measure.label(np.array(ic)) # segment image
# plt.imshow(all_labels); plt.show() # debug: show image
text = dict()
# create a list of only the letters being 1, ignore the background with >10000 pixels
letters = [all_labels == color for color, cnt in Counter(all_labels.reshape(-1)).items() if cnt < 10000]
positions = [list(np.where(letter)) for letter in letters]
for letter, position in zip(letters, positions):
pad = 2 # padding
minx = min(position[0])-pad
maxx = max(position[0])+pad
miny = min(position[1])-pad
maxy = max(position[1])+pad
# skip very small items as they are probably an error
size = (maxx-minx)*(maxy-miny)
if size < 100:
continue
sub_image = np.array(img)[minx:maxx, miny:maxy].astype(np.uint8)
pil_image = Image.fromarray(sub_image > 0).resize((28,28))
# plt.imshow(sub_image, cmap="gray"); plt.show(); # for debugging initial digits
# text[miny] = tr.ocr_image(pil_image) # didn't fully work for me
text[miny] = classify(pil_image)
pil_image.save(f"letters/{text[miny]}/{random.random()}.png") # collect data to improve/retrain the classifier
detected = "".join([text[pos] for pos in sorted(text)])
# plt.imshow(img, cmap="gray"); plt.show(); print(detected)
return detected
# MAIN LOGIC
sess = requests.Session()
reg = "http://tasks.aeroctf.com:40000/reg.php"
gen = "http://tasks.aeroctf.com:40000/gen.php"
while True:
png = sess.get(gen).content
img = Image.open(BytesIO(png))
capcha = detect(img)
oresponse = sess.post(reg, data={"captha":capcha}).text
if "Captcha" in oresponse:
pos = oresponse.index("Captcha")
response = int(oresponse[pos:pos+20].split(" ")[1])
if response % 10 == 0: print(response, end=" ")
if response == 0: plt.imshow(img, cmap="gray"); plt.show(); print(capcha)
else:
# print(oresponse)
print(sess.cookies)
break
Code build model
from __future__ import print_function
import tensorflow.keras as keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.utils import to_categorical
import os
import numpy as np
import random
from PIL import Image
batch_size = 64
num_classes = 16
epochs = 50
# input image dimensions
img_rows, img_cols = 28, 28
def load_data():
trainx, testx, trainy, testy = [], [], [], []
for dir in os.listdir("letters"):
for file in os.listdir("letters/"+dir):
img = Image.open("letters/"+dir+"/"+file)
img = np.array(img.getdata())
id = dir.replace("A", "10").replace("B", "11").replace("C", "12").replace("D", "13").replace("E", "14").replace("F", "15")
if random.random() < 0.9:
trainx.append(img); trainy.append(int(id))
else:
testx.append(img); testy.append(int(id))
return (np.array(trainx), trainy), (np.array(testx), testy)
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(learning_rate=0.1),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
model.save("model.keras")
print('Test loss:', score[0])
print('Test accuracy:', score[1])